
Intro
To fully understand all words used across article - please refer to domain page.
Databases in microservices world
Databases … yes databases. In new microservice architecture world so much impact is put on serverless or function style components, where stateless code wins. And obviously that’s a great idea, when you have no state you have no need to synchronize nor to lock. Scaling is the matter of replication and understanding of flow is obvious in a immutable world.
But still - can you imagine product bringing business value which does not handle state? Let’s imagine identity management - this always will require to store some user info. Some may say but you know, there is google, github, and other OAuth which handles that for you - sure but it simply means you are using external service to store the data - still you need somewhere db to exist.
Anyway, let’s go back to JAlgoArena world. In this post I would like you to show how I dealt through months with data and how different problems moved me to different solutions.
On the beginning it's simple, is it?
When I started first prototype of JAlgoArena there was no separate storage tool, and design was very simple:
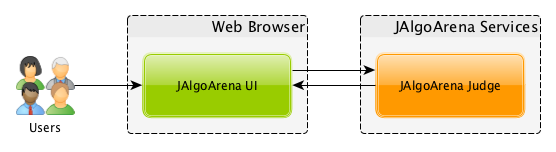
State was there, but it was just hardcoded within Judge microservice. Not very useful for production use case, right?
That was the time when I started to think what should I choose, and how it should look like. By whole the time I had in my mind the pattern that every microservice should have own database - and by the best efforts it should not be shared.
Ok, I had already experience with Mongo DB and I loved how it managed state. Although I wanted more embedded approach, when I can keep database really close to microservices. Lets see my first approach to real world storage handling:
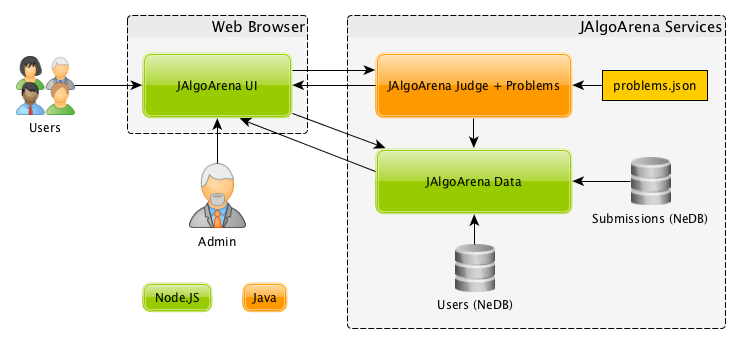
Great - in here I was not yet great with all DDD approaches and domain separation, so please excuse me ;) My initial understanding of database per microservices moved me to idea - so let’s do a microservice with a responsibility for dealing with a data (I know, I know … it was not best idea)!
As my research went, I found NeDB as a great solution, I had my brand new NodeJS microservice and could deal with data there. In reality - as you see on diagram I used json file for handling problems data - so NeDB was not my only choice.
The solution was pretty easy, you could save incoming json and then query for it (you can still check it on GitHub page). I was creating new file based storage for both contexts: users and submissions to keep them separate. By the way - it was first sign of keeping two responsibilities within single service. Creating database was fairly easy, there was simple code to create it:
var Datastore = require('nedb');
module.exports = function (filename, logger) {
var db = new Datastore({filename: filename, autoload: true});
db.loadDatabase(function (err) {
if (err) {
logger.error(err);
} else {
logger.debug("DB loaded: " + filename);
}
});
return db;
};
Querying submissions looked like:
submissionDb.find({userId: newSubmission.userId}, function (err, docs) {
if (err) return next(err);
return res.json(docs);
});
All database operations you can find in submissions.js, and all users ones in passport.js.
By the way, another insight I would have on below was that database code was coupled with business logic - which in reality should be handled by some repositories.
As you see above, it was a bit better (finally we have real storage!) approach, but far from being ideal and we did not touch even scalability issues.
Oh … one more point. At that time it was when I decided keeping problems within json was not a good idea. You know, we need the database ;)

Interestingly, at some of current versions I’ve reverted that approached and went back for json - as it’s best serving this kind of data - and that’s what I love about microservices. Keeping them small and decoupled allows on quick and easy changes, even rewrite of whole service when needed :)
Database per microservice
Ok, my whole soul, mind and body was fulfilled with the idea - keep database specific to microservice. And again, I wanted to use something which can sit together with microservice - use some kind of embedded database and make usage of it as simple as possible. Oh - and I wanted to switch to Spring Boot which is de facto widely standard within Java ecosystem for creating microservices.
I looked for quite a while, compared different approaches and finally found - Xodus. However badly the name sounds, it’s pretty decent database created by JetBrains. JetBrains Xodus is a Java transactional schema-less embedded database - and they use it for own products e.g. JetBrains YouTrack. You may read more about it in here. Just to be clear, it’s not a kindergarten tool, it is serious database capable to handle terabytes of data having transactions on board.
Let’s see how it impacted the architecture:

Besides of the fact that whole architecture grew to use Service Discovery approach, now you can see every microservice own separate database. Let’s see how some of the repository methods are implemented within Kotlin using Xodus:
fun findAll(): List<Problem> {
return readonly {
it.getAll(Constants.ENTITY_TYPE).map { Problem.from(it) }
}
}There is bit of Kotlin know how to decrypt it - but it’s enough to understand that it is a thing passed from readonly method, which looks like:
private fun <T> readonly(call: (PersistentStoreTransaction) -> T): T {
return store.computeInReadonlyTransaction {
call(it as PersistentStoreTransaction)
}
}As you see, it’s just wrapping the code into readonly transaction (btw, such structures is why I love Kotlin) and passing store down to method, where we invoke getAll describing our entity name, and finally using Kotlin streams to map outgoing problems.
To make a full picture, let’s see how write transaction looks like:
private fun <T> transactional(call: (PersistentStoreTransaction) -> T): T {
return store.computeInTransaction { call(it as PersistentStoreTransaction) }
}And then how it is used to update existing items:
override fun addOrUpdate(problem: Problem): Problem {
return transactional {
val existingEntity = it.find(
Constants.ENTITY_TYPE, Constants.problemId, problem.id
).firstOrNull()
val entity = when (existingEntity) {
null -> it.newEntity(Constants.ENTITY_TYPE)
else -> existingEntity
}
updateEntity(entity, problem)
}
}
private fun updateEntity(entity: Entity, problem: Problem): Problem {
entity.apply {
setProperty(Constants.problemId, problem.id)
setProperty(Constants.problemTitle, problem.title)
setProperty(Constants.problemDescription, problem.description)
setProperty(Constants.problemLevel, problem.level)
setProperty(Constants.problemTimeLimit, problem.timeLimit)
setProperty(Constants.problemFunction, toJson(problem.func!!))
setProperty(Constants.problemTestCases, toJson(problem.testCases!!))
}
return Problem.from(entity)
}Full source code is available in here - XodusProblemRepository.kt.
This approach worked for quite a while - and I run few AlgoCup contest using it in production environment without any issues, or closely without any issues ;)
The biggest challenge was, that any single component which was using it was hard to scale horizontally. If I start replicating services, how do I synchronize those file based storage instances?
And there was actually partial rescue:

That was huge change for a platform - making it reactive with all the writes (besides of creating accounts). That allowed to keep data log with Kafka, and replicate as many instances of Ranking or Submissions services as we want. But … there is always some but ;)
Authentication was not coming through Apache Kafka. Till security is introduced within JAlgoArena on Apache Kafka level, I cannot imagine keeping there user names and passwords and recover from it ;) The only choice is to still use synchronous approach - so we cannot scale in here with Xodus database - we need scalable storage by itself and it’s hard to achieve with embedded storage.
Scalability matters - Cockroach DB coming
Initially there was a plan to use Cassandra - I knew it, I used it, it was scalable and well known database. Although there were few buts:
- it’s complex to operate
- it’s written in java, far from memory consumptions we have with C++ implementations
- the support within frameworks is not that matured as with old good SQL databases
But how do I find database which is easy to operate with, scalable, ideally having SQL interface which would allow on reusing existing libraries (why not?) and of course, being open source and free for my usage.
And you know what? I found it! I was so excited when I firstly heard about Cockroach DB. Btw, watch the movie there, it’s great show case on what Cockroach DB is.
Finally I get to the point where I can easily scale any kind of storage dependent database, having cloud friendly db on board:

There was few other changes happening, but that’s how architecture looks like when I have just two types of data to store and scale: submissions and users. And you know what? Now I can use all goodies that frameworks brings for SQL world, or to be more specific in here - Postgres SQL dialect.
Let’s look on example repository how it looks like, considering that with Spring Boot and JPA I only need to specify interface:
interface SubmissionsRepository : JpaRepository<Submission, Int> {
fun findByUserId(userId: String): List<Submission>
fun findBySubmissionId(submissionId: String): Submission?
fun findByProblemId(problemId: String): List<Submission>
fun findBySubmissionTimeLessThan(tillDate: LocalDateTime): List<Submission>
}As you see it’s very easy and convenient now to implement interface to data storage, see full source here.
Again, using it is like using plain Java interface
val submissionsRepository: SubmissionsRepository
fun findAll(): List<RankingSubmission> = try {
submissionsRepository.findAll().map {
RankingSubmission(
it.id!!,
it.problemId,
it.statusCode,
it.userId,
it.submissionTime,
it.elapsedTime
)
}
} To check full sources, take a look in here.
It’s worth to mention, that thanks to using common interface (JPA) - I can plug embedded H2 database with just proper test configuration properties - making it easy to test based on specified interfaces and domain classes.
Specifying domain is extremely easy too, let’s check our object model for submission:
@JsonIgnoreProperties(ignoreUnknown = true)
@Entity
@Table(name = "submissions")
data class Submission(
@Column(nullable = false)
var problemId: String = "",
@Column(nullable = false, length = 20000)
var sourceCode: String = "",
@Column(nullable = false)
var statusCode: String = "NOT_FOUND",
@Column(nullable = false)
var userId: String = "",
@Column(unique = true, nullable = false)
var submissionId: String = "",
@Column(nullable = false)
var submissionTime: LocalDateTime = LocalDateTime.now(),
@Column(nullable = false)
var elapsedTime: Double = -1.0,
@Column(nullable = false)
var consumedMemory: Long = 0L,
@Column(length = 20000)
var errorMessage: String? = null,
var passedTestCases: Int? = 0,
var failedTestCases: Int? = 0,
var token: String = "",
@Id @GeneratedValue(strategy = GenerationType.AUTO)
var id: Int? = null
)And generated SQL based on above:
CREATE TABLE IF NOT EXISTS jalgoarena.submissions (
id INTEGER NOT NULL,
consumed_memory BIGINT NOT NULL,
elapsed_time DOUBLE PRECISION NOT NULL,
error_message STRING(20000) NULL,
failed_test_cases INTEGER NULL,
passed_test_cases INTEGER NULL,
problem_id STRING(255) NOT NULL,
source_code STRING(20000) NOT NULL,
status_code STRING(255) NOT NULL,
submission_id STRING(255) NOT NULL,
submission_time TIMESTAMP NOT NULL,
token STRING(255) NULL,
user_id STRING(255) NOT NULL,
CONSTRAINT "primary" PRIMARY KEY (id ASC),
UNIQUE INDEX uk_51d698q9pdvfldc75kskyxmlf (submission_id ASC),
FAMILY "primary" (id, consumed_memory, elapsed_time, error_message, failed_test_cases, passed_test_cases, problem_id, source_code, status_code, submission_id, submission_time, token, user_id)
);Old good SQL :)
As you see it’s very easy to deal with software development using it, but how about deployment and operations? Firstly, it’s worth to say that Cockroach DB comes with administration console. As it’s written in Go Lang, deploying it is the matter of deploying docker image or binary - which makes it extremely easy to install.
Take a look on Nomad job specification for downloading, installing and running cockroach db (full sources):
artifact {
source = "https://binaries.cockroachdb.com/cockroach-v2.0.4.linux-amd64.tgz"
}
config {
command = "local/cockroach-v2.0.4.linux-amd64/cockroach"
args = [
"start",
"--insecure",
"--store=node1",
"--host", "${NOMAD_IP_tcp}",
"--port", "${NOMAD_PORT_tcp}",
"--http-port", "${NOMAD_PORT_http}",
"--join", "${COCKROACH_MASTER_HOST}"
]
}And here we are, happy with pretty decent easy to operate and scalable database, ready for exciting future!
Last note
As you probably remember, I wrote above:
Ok, my whole soul, mind and body was fulfilled with the idea - keep database specific to microservice.
And again we left with single database, so how is it? In here I still have some doubts and open questions, more about pragmatism or laziness versus best practices. I have cluster representing my storage, which is used by two different services. They share database, although not using the other ones tables - which means responsibility is fairly divided.
I think somewhere in the future I will just run two separate Cockroach DB clusters, as it’s pretty easy to setup them,
although still thinking about the value it would provide vs cost. Usually automation is solution, as with single click
or command there is almost no additional cost of running separate instance - maybe just money it will eat on cloud where
you setup whole database cluster to just handle single table - that’s something which still argues in my mind and pragmatism
together with his friend common sense tells me to just keep single cluster ;)